Scenario 1: When there are difference rows in one of the sources and both the sources are either flat files or a flat file and a relational table.
To illustrate this scenario, the two sources considered are two comma separated flat files - EMPLOYEE_FILE_1.txt and EMPLOYEE_FILE_2.txt. The EMPLOYEE_FILE_2.txt has some extra records that need to be reported or loaded into the target which is a relational table having the same definition as the sources. The difference rows between the two flat files are highlighted in red as shown below.

Import the two flat file definitions using the Source Analyzer in Informatica PowerCenter Designer client tool as shown below.

Create a new mapping in the Mapping Designer and drag the two source definitions into the workspace.
Now, to identify the extra records from EMPLOYEE_FILE_2, a Joiner transformation followed by a Filter transformation is used.
The illustration discussed below uses an unsorted Joiner Transformation and since both the sources are having few records, any one of the sources can be treated as the "Master" source. Here the EMPLOYEE_FILE_1 source is designated as the "Master" source. In practice, however, to improve performance for an unsorted joiner transformation, the source with fewer rows is treated as the "Master" source while for a sorted joiner transformation, the source with fewer duplicate key values is assigned as the "Master" source.
First drag all the ports from the source qualifier SQ_EMPLOYEE_FILE_2 into the joiner transformation. Notice the ports created in the joiner transformation are designated as the "Detail" source by default. Drag only the EMP_ID port from SQ_EMPLOYEE_FILE_1 into the joiner transformation as shown below.
Double-click the joiner transformation to open up the Edit view of the transformation. Click on the Condition tab and specify the condition shown below.
Since, we need to pass all the rows from the EMPLOYEE_FILE_2, the Join Type used is "Master Outer Join" in the Properties tab as shown below. This will ensure that all the rows from the "Detail" source and only the matching rows from the "Master" source will pass from the joiner transformation.
The Join types supported in the joiner transformation are described below.

The rows passed by the joiner transformation are shown below. For the missing rows in the "Master" source, the EMP_ID1 value is NULL.

Now, a filter transformation can be used ahead to pass only the records having EMP_ID1 as NULL since these rows correspond to the difference rows from EMPLOYEE_FILE_2 source. Pass all the rows from the joiner transformation into the filter transformation and add the Filter condition shown below in the Properties tab of the filter transformation.
The records passed by the filter transformation are shown below.

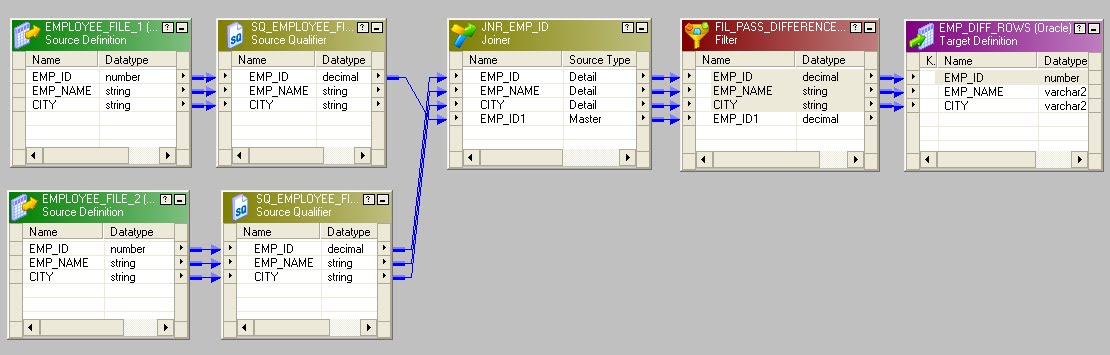
Link the EMP_ID, EMP_NAME and CITY ports to the target definition. The complete mapping is shown below.
Create a session task and a workflow. After running the workflow, the difference rows loaded into the target relational table are shown below.

Scenario 2: When there are difference rows in both the sources and both the sources are either flat files or a flat file and a relational table.
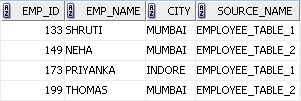
For this illustration, we consider both the sources are flat files. The difference rows in both the flat files are highlighted in red. The target relational table has an additional column SOURCE_NAME added, which indicates the source name where the difference row is present.

The EMPLOYEE_FILE_1 is treated as the "Master" source again for the unsorted joiner transformation. All the ports from the source qualifier SQ_EMPLOYEE_FILE_1 are passed to the joiner transformation as shown below because the difference records are present in both the sources.
The join condition for the joiner transformation is the same as the first scenario, but for this case, the Join Type is Full Outer Join as shown below.
The rows passed by the joiner transformation are shown below. For the missing rows in the "Master" source, the EMP_ID1, EMP_NAME1 and CITY1 values are NULL, while for the missing rows in the "Detail" source, the EMP_ID, EMP_NAME and CITY values are NULL.

The filter transformation shown below should only pass the rows having NULL values in EMP_ID or EMP_ID1 ports as these correspond to the difference rows in the EMPLOYEE_FILE_2 and EMPLOYEE_FILE_1 flat files respectively.
The filter condition used in the filter transformation is shown below.

The filter transformation passes the following rows.

Now, add an expression transformation after the filter transformation. Pass all the ports from the filter transformation to the expression transformation. The expression transformation should have the following ports in the order shown below.
The logic for the output port EMP_ID_OUT is that if the EMP_ID value from EMPLOYEE_FILE_2 source is NULL, pass the EMP_ID1 value from the EMPLOYEE_FILE_1 source, else return the EMP_ID value from EMPLOYEE_FILE_2 source. This logic works because for any row passed from the filter transformation, either the row from the "Master" source will have NULL values or the row from the "Detail" source will have NULL values. A similar logic is applied for the EMP_NAME_OUT and CITY_OUT output ports.
Another output port SOURCE_NAME_OUT is used to determine the source of the difference row. The expression used for this port is shown below.

The complete mapping is shown below.

Create a session task and a workflow. After running the workflow, the difference rows loaded into the target relational table are shown below.

Scenario 3: When there are difference rows in two relational tables residing in the same database.
For this illustration, two relational tables EMPLOYEE_TABLE_1 and EMPLOYEE_TABLE_2 having the same definition are considered. The rows present in both the tables are shown below and the difference rows are highlighted in red.

Import the table definition of any one source in the Source Analyzer. Here, the EMPLOYEE_TABLE_1 source definition is imported.

A simple SQL query that returns the difference rows in EMPLOYEE_TABLE_1 is given below.
SELECT EMP_ID, EMP_NAME, CITY FROM EMPLOYEE_TABLE_1 EMP_1
WHERE NOT EXISTS (SELECT EMP_ID FROM EMPLOYEE_TABLE_2 EMP_2
WHERE EMP_1.EMP_ID = EMP_2.EMP_ID)
WHERE NOT EXISTS (SELECT EMP_ID FROM EMPLOYEE_TABLE_2 EMP_2
WHERE EMP_1.EMP_ID = EMP_2.EMP_ID)
SELECT EMP_ID, EMP_NAME, CITY, 'EMPLOYEE_TABLE_1' AS SOURCE_NAME
FROM EMPLOYEE_TABLE_1 EMP_1
WHERE NOT EXISTS (SELECT EMP_ID FROM EMPLOYEE_TABLE_2 EMP_2
WHERE EMP_1.EMP_ID = EMP_2.EMP_ID)
UNION
SELECT EMP_ID, EMP_NAME, CITY, 'EMPLOYEE_TABLE_2' AS SOURCE_NAME
FROM EMPLOYEE_TABLE_2 EMP_2
WHERE NOT EXISTS (SELECT EMP_ID FROM EMPLOYEE_TABLE_1 EMP_1
WHERE EMP_1.EMP_ID = EMP_2.EMP_ID)
Add the above query to the source qualifier transformation in the Sql Query attribute value as shown below. This will override the default SQL query issued when the session runs. Ensure that the order of the columns in the SQL query match the order of the ports in the Source Qualifier.
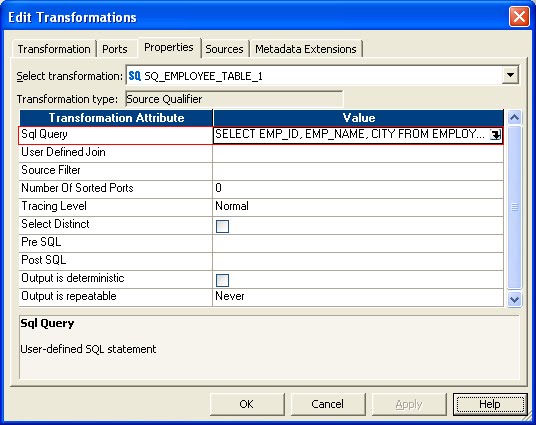
The alias column 'SOURCE_NAME' value also needs to be passed to the target. For this purpose, a new port SOURCE_NAME is created in the source qualifier as shown below.

By default, all ports that are in the source qualifier are input/output ports. Hence, the new port SOURCE_NAME that is created should be linked to a field from the source definition having the same datatype i.e. the datatype varchar2 in the source definition changes to string in the source qualifier. If the port SOURCE_NAME is not linked, the session will fail with an error - TE_7020 Internal error. The Source Qualifier [SQ_EMPLOYEE_TABLE_1] contains an unbound field [SOURCE_NAME].
Link the CITY port from the source definition to the SOURCE_NAME port in the source qualifier. As a good practice, use an expression transformation in between the source qualifier and the target definition as shown below.

Create a session task and a workflow. After running the workflow, the difference rows loaded into the target relational table are shown below.